August 31, 2008
I recently got a new book to read, From Gestalt Theory to Image Analysis, A Probabilistic Approach by Desolneux, Moisan, and Morel. I’ve heard of Gestalt before – apparently it’s a psychology theory of the mind. There is also an image analysis angle as Gestalt is a German word for “form” or “shape”. In the introduction the book presents are few Gestalt principles and gives them a mathematical interpretation. One principle I found especially relevant.
Werthheimer’s contrast invariance principle: Image interpretation does not depend on actual values of the gray levels, but only their relative values.
As the book further explains, the principle comes from the fact that one shouldn’t expect or rely on precise measurements of intensity. Once again this is our example:
 
The second part of the principle suggests that one should look at the level sets of the gray scale function, as well as sub- and supra-level sets. In the blurred image above, the circle is still recognizable regardless of the low contrast. Which should be picked to evaluate the size of the circle is ambiguous however.
   
So far, so good. Unfortunately, next the authors concentrate on supra-level (or “upper level”) sets exclusively. This is a common approach. The result is that you recognize only light objects on dark background. To see dark on light will take an extra step (invert colors). Meanwhile the case of objects with holes (or dark spots on light objects) becomes really messy. Our algorithm builds the hierarchy of dark and- light objects in one sweep (see Topology graph).
The book isn’t really about Werthheimer’s principle but another one (more of a definition).
Helmholtz principle: Gestalts are sets of points whose (geometric regular) special arrangements could not occur in noise.
This should be interesting…
August 24, 2008
Previously we discussed the watershed algorithm for binary images. One thing that wasn’t explained was where the name comes from.
We start with the following approach. According to Gonzales and Woods: “we think of a gray scale image as a topological surface, where the values of f(x,y) are interpreted as heights.” This is good (except the redundant “topological”) and quite clear. Mathematically, if f(x,y) gives the value of gray of the pixel (x,y), we simply end up with the -graph of f (remember precalc?).
 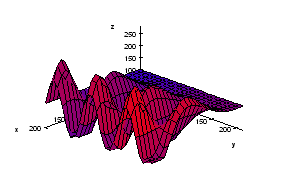 
Next, we find the “catchment” basins. Mathematically, these are minimum points of the surface. However, to find basins’ borders we need to find the ridge lines that separate them. Mathematically, those are lines that go from one maximum point to another via the saddle points.
To summarize, we create a surface from the image by using the value of gray at a given pixel as the height of the surface above it. The light areas are the peaks and the dark areas are the valleys. Next, we flood the valleys, gradually. As we do that, we don’t allow the water to flow from one valley to another. How? By building dams. These dams will break the image into regions each containing a single valley. That’s image segmentation.
Let’s now take a look at the Wikipedia article: “The watershed algorithm is an image processing segmentation algorithm that splits an image into areas, based on the topology of the image.” First, any segmentation algorithm splits an image into areas. Second, any segmentation should be based on the topology of the image. So, what’s left is “The watershed is an image segmentation algorithm”.
The next sentence is “The length of the gradients is interpreted as elevation information.” Wait a minute, that’s not the same! The length of the gradient is the steepness of the surface. In the next sentence however the article seems comes back to the standard approach: “During the successive flooding of the grey value relief, watersheds with adjacent catchment basins are constructed.” And then again: “This flooding process is performed on the gradient image…” Using the gradient as the surface is an alternative approach to the watershed, so this must be a mix-up. Another approach is using the distance function for binary images.
We’ll discuss these issues in the next post.
June 29, 2008
According the ImageJ site: “Watershed segmentation is a way of automatically separating or cutting apart particles that touch”.
Suppose black is the particles and white is the background. The the procedure is fairly simple.

First, for each pixel compute the distance to the nearest white pixel. This is called the distance function. It’s a scalar function of two variables.
Next, find the maximum points of this function. Each of these pixels will become the center of a particle.
You carry out multiple rounds of dilation that gradually grow these particles. The dilation has two restrictions. First, the particles aren’t allowed to grow beyond the original set of black pixels. This way we guarantee that we end up with the same set of pixels except it has been “cut” into pieces. Second, a new pixel isn’t added if it’s adjacent to a pixel that belongs to another particle. This way the particles start to “push” onto each other but never overlap.
The tricky part of the last restriction is that the growth rate will have to be different for particles of different sizes. Otherwise, two particles will always be separated by a cut exactly half way between their centers. That wouldn’t make sense if one is significantly larger than the other. Roughly, the dilation rate should be proportional to the value of the distance function.
 
Some questions remain. For example, how does one efficiently find the maxima? Everything is discrete, so forget about partial derivatives etc. You have to visit every point.
How does one deal with particles that are simply noise? If you remove all small particles, you may have nothing left. One answer is to discard the maxima with low values of the distance function.
Another issue is typical for many image analysis techniques. Once again to quote the ImageJ site, “Watershed segmentation works best for smooth convex objects that don’t overlap too much.” Basically, you have to view (analyze!) the image yourself and decide ahead of time whether the method is appropriate. There is a good reason to be cautious – non-convex particles may cause the watershed method to produce undesirable results.
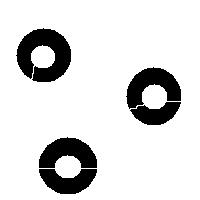
You have to choose ahead of time whether you have white or black particles. If you don’t do it correctly, you end up with non-convex black “particles”. The result of watershed segmentation isn’t what you expect:
 
It is also easy to think of an image (rings) that can’t possibly be analyzed correctly by watershed regardless of the black/white choice:
  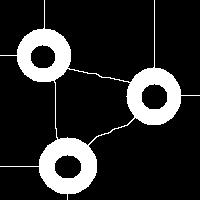
Needless to say that the topological method produces the correct segmentation here:
 
It can’t however separate particles yet (the stuff will appear in the wiki under Robustness of topology).
June 15, 2008
Let’s go to Wikipedia. The first sentence is:
“Image segmentation is partitioning a digital image into multiple regions”.
 This description isn’t what I would call a definition as it suffers from a few very serious flaws. This description isn’t what I would call a definition as it suffers from a few very serious flaws.
First, what does “partitioning” mean? A partition is a representation of something as the union of non-overlapping pieces. Then partitioning is a way of obtaining a partition. The part about the regions not overlapping each other is missing elsewhere in the article: “The result of image segmentation is a set of regions that collectively cover the entire image” (second paragraph).
Then, is image segmentation a process (partitioning) or the output of that process? The description clearly suggests the former. That’s a problem because it emphasizes “how” over “what”. That suggests human involvement in the process that is supposed to be objective and reproducible.
Next, a segmentation is a result of partitioning but not every partitioning results in a segmentation. A segmentation is supposed to have something to do with the content of the image.
 More nitpicking. Do the regions have to be “multiple”? The image may be blank or contain a single object. Does the image has to be “digital”? Segmentation of analogue images makes perfect sense. More nitpicking. Do the regions have to be “multiple”? The image may be blank or contain a single object. Does the image has to be “digital”? Segmentation of analogue images makes perfect sense.
A slightly better “definition” I could suggest is this:
A segmentation of an image is a partition of the image that reveals some of its content.
This is far from perfect. First, strictly speaking, what we partition isn’t the image but what’s often called its “carrier” – the rectangle itself. Also, the background is a very special element of the partition. It shouldn’t count as an object…
Another issue is with the output of the analysis. The third sentence is “Image segmentation is typically used to locate objects and boundaries (lines, curves, etc.) in images.” It is clear that “boundaries” should be read “their boundaries” here - boundaries of the objects. The image does not contain boundaries – it contains objects and objects have boundaries. (A boundary without an object is like Cheshire Cat’s grin.)
Once the object is found, finding its boundary is an easy exercise. This does not work the other way around. The article says: “The result of image segmentation [may be] a set of contours extracted from the image.” But contours are simply level curves of some function. They don’t have to be closed (like a circle). If a curve isn’t closed, it does not enclose anything – it’s a boundary without an object! More generally, searching for boundaries instead of objects is called “edge detection”. In the presence of noise, one ends up with just a bunch of pixels – not even curves… And by the way, the language of “contours”, “edges”, etc limits you to 2D images. Segmentation of 3D images is out of the window?
I plan to write a few posts about specific image segmentation methods in the coming weeks.
June 2, 2008
In part 1 and part 2 I discussed a paper on face recognition and the methods it relies on. Recall, each 100×100 gray scale image is a table of 100×100 = 10,000 numbers that can be rearranged into a 10,000-vector or a point in the 10,000-dimensional Euclidean space. As we discovered in part 2, using the closedness of these points as a measurement of similarity between images ignores the way the pixels are attached to each other. A deeper problem is that unless the two images are aligned first, there is no way to use this representation to discover that they depict the same or similar thing. The proper term for this alignment is image registration.
The similarity between images represented this way will be entirely based on their overlap. As result, the distance can be large even between images that we would consider similar. In part 2 we had examples of one-pixel images. More realistic examples are these:
- image with an object in one corner onewith the same object in another corner;
- image of a cross and the same cross turned 45 degrees;
- etc.
Back to face identification. As the faces are points in the 10,000-dimensional space, these points should be grouped somehow. The point is that all images of the same individual should belong to one group and not any other. It is common to consider “clusters” of points, i.e., groups formed of point close to each other. This was discussed above.
Now, in this paper the approach is different: a new point (the face to be identified) is represented as a linear combination of all other points (all faces in the collection).
As we know from linear algebra, this implies the following. (1) the entire collection has to be linearly dependent, (2) you can find a subcollection that adds up to 0! In other words, everything cancels out and you end up with a blank photo. Is it possible? If the dimension is low or the collection is large (the images are small relative to the number of images), maybe. What if the collection is small? (It is small – see below.) It seems unlikely. Why do I think so? Consider this very extreme case: you may need the negative for each face to cancel it: same shape with dark vs. light hair, skin, eyes, teeth (!).…
Second, the new image in the collection has to be a linear combination of training images of the same person. In other words, any image of person A is represented as a linear combination of other images of A in the collection, ideally. (More likely this image is supposed to be closer to the linear space spanned by these images.) The approach could only work under the assumption that people are linearly independent:
No face in the collection can be represented as a linear combination of the rest of the faces.
It’s a bold assumption.
If it is true, then the challenge is to make the algorithm efficient enough. The idea is that you don’t need all of those pixels/features and they in fact could be random. That must be the point of the paper.
The testing was done on two collections with several thousand images each. That sounds OK, but the number of individuals in these collections was 38 and 114!
To summarize, there is nothing wrong with the theory but its assumptions are unproven and the results are untested.
P.S. It’s strange but after so many years computer vision still looks like an academic discipline and not an industry.
May 27, 2008
TinEye is an image-to-image search engine from Idée. It is in a closed testing but I got to try it a couple of days ago. After a very positive review at TechCrunch, I decided to write up my impressions (a review of an earlier version is here).
They don’t make wild claims about being able to do face identification or similar (unsolved) problems. The goal seems very simple: find copies of images. With this task TinEye does a fairly good job. It finds even ones that have been modified - noise, color, stretch, crop, some photoshopping. It does not do well with rotation. That’s a major drawback (compare to Lincoln from MS Research).
These are the images that I tried.
  
Barbara: found both color and bw copies and a slightly cropped version.
Marilyn: found cropped and stretched versions, and an even edited (defaced) version.
Lenna: found both color and bw, but not partial or rotated versions (even though a rotated version is in the index).
May 2, 2008
I read this press release a few weeks ago. Just like many others it presents some over-optimistic report of a new method that is supposed to solve a problem. Just like many others it’s about face recognition. For a change I decided to read the paper the report is based on and write up my thoughts.
First, the paper itself is much more modest that the press release. That’s very common. Let’s look closer.
The traditional approach to face identification is to look for distinctive features – eyes, nose, mouth - and then match them with those of the other image or images. Here approach is to take everything in the image, every “feature”. First, let’s make this clear: when they say “features” they mean simply pixels! I have no idea why… They also don’t emphasize the obvious consequence – the method should work with any images not just faces.
This language of “features” obscures a common and straightforward approach to data representation and pattern recognition, as follows. Suppose you have a collection of 100×100 images. Then you rearrange the rows of this 100×100 “matrix” into a 10,000-vector. As a result, each image is represented as a point in the 10,000-dimensional space. This is clearly a brute force approach. However, something like that is inevitable if you don’t have an insight into the nature of the problem. Once all the data is in a Euclidean space (no matter how large), all statistical, data processing and pattern recognition methods can be used. Nice! The most common method is probably clustering – looking for groups of points unusually close to each other.
I have always felt OK about this approach but this time I started to doubt its applicability in analysis of images.
First you notice is that this approach can only work as long as all images have the same dimensions. It gets trickier if you study images of different dimensions. For example, if you had both 30×20 images and 1×600 images in the collection, that would really mess up everything! In a less extreme case, the presence of 30×20 and 20×30 images in the collection would be a problem. Of course you can simply add extra blank pixels up to 30×30 as a “common denominator”. However, it appeared to me that such a problem (and such an awkward solution) may be an indication of bigger issues with the whole approach.
I asked myself, does this approach preserve the structural information contained in the image? The very first thing to look at is the adjacency of pixels. Since each pixel corresponds to an independent dimension, it seems that the adjacency is still contained in those coordinates: (a,b,…) is not the same as (b,a,…). Wrong!
It suffices to look at the distance between points – images - in this 10,000-dimensional space. It can be defined in a number of ways, but as long as it is symmetric we have a problem. Suppose the distance between (1,0,…,0) and (0,1,0,…,0) is d. Then the distance between (1,0,…,0) and (0,0,…,0,1) is also d. Here (1,0,…,0) and (0,1,0,…,0) are two images with a single pixel in each – located adjacent to each other - while (0,0,…,0,1) has a pixel in the opposite corner! The result is odd and you have to ask yourself, can clustering be meaningful here?
More to come…
April 29, 2008
A paper appeared recently on how to improve Google search. It has received a lot of media coverage including NY Times and TechCrunch. Since this is a topic that interests me a lot, I decided to write a few words.
The most important thing to understand here is that the paper isn’t about improving image search in general (especially visual image search and CBIR, see here). It is specifically about Google image search (and indirectly other search engines, MSN, Yahoo, etc). The goal is to improve it (because it sucks). It is currently based on surrounding text and as a result you get a lot of irrelevant images. Essentially, they add to this approach some image analysis. What kind? Not the best kind – “descriptors”. So there will be no analysis of the content of the image (see Fields related to computer vision). Even so, the descriptors will help to evaluate similarity between images - to a certain degree.
To summarize, some similarity measure plus hyperlinks - that will help with improving the search results for sure. Meanwhile, image search, image recognition etc remain unsolved.
April 26, 2008
I was reading this interview with Donald Knuth and “literate programming” was mentioned. I went to their site and this is what explained to me what it’s about:
Instead of writing code containing documentation, the literate programmer writes documentation containing code.
Suddenly I realized: that’s it! That’s what I’ve been trying to do in the wiki. It should be text illustrated with code not vice versa. Interesting…
April 13, 2008
Guest post by Ash Pahwa.
CellProfiler was developed at Whitehead Institute for Biomedical Research and MIT by Anne Carpenter’s group. This software is designed for mass processing of bio-medical images. The main focus of the software is to identify and quantify cell phenotypes. I tested CellProfiler version number 1.0.4628 published on April 23, 2007. It is an open source software that also works with Open Microscopy Environment (OME). The software is an interface tool for MATLAB and it comes with a runtime version of MATLAB.
The unique feature of CellProfiler is that it allows mass processing of images. User specifies two items. First, the folder name where the images are stored. And second, a list of operations that need to be performed on the images. This list of operations is called a “pipeline”. Once both items are specified, the processing starts and all the operations specified in the pipeline are performed on all the images. The result of all the operation can be exported to a database or Excel spreadsheet. However, CellProfiler does not have such database management capabilities as cellAnalyst.
The standard operations are as follows:
- Cell counting,
- Cell size,
- Cell identification,
- Per-cell protein levels,
- Cell shape,
- Sub-cellular levels of DNA,
- Protein staining.
Besides these features CellProfiler also provides many other advanced image processing tools used primarily with the biomedical images. Since CellProfiler is an interface from the image processing tool box of MATLAB (IPT), all the IPT functions can also be applied to the images; for example, special filters, histogram equalization, frequency filters etc. User has the ability to write his own MATLAB scripts for custom image processing tasks. The primary market of this product is a place where images are being captured in high quantities. Individual image analysis is not possible in these conditions. In these circumstances CellProfiler can used to analyze the images while saving time as well as improving accuracy of the analysis.
March 28, 2008
Here I finish (part 1 and part 2) my short review of Quantitative Biological Image Analysis by Erik Meijering and Gert van Cappellen.
The last two items on the list of fields are the following.
Computer Graphics: numbers in -> image out. Instead of numbers one could have math functions that produce numerical descriptions of images. These descriptions are likely to be different from those in computer vision: vector vs. raster images (the difference is in fact superficial from the point of view of cell decomposition). It’s also “the inverse of image analysis”. That would seem to imply that if you use Image Analysis followed by Computer Graphics you’ll end up with the original image. That would make sense only if the data produced by image analysis does not go very deep (not image segmentation or Fourier transform etc). I think that Computer Graphics is simply irrelevant for Computer Vision.
Visualization: image in -> representation out. The idea is that high dimensional image data is transformed into a more primitive representation. Displaying contours of objects is an example of that, illustrated below with Pixcavator. “Pseudocoloring” is an interesting subtopic here even though it can be also classified as image processing.
In conclusion, a couple of quotes from the article. In spite of the disagreement, I am glad that there are people thinking about these issues.
Although it is certainly possible to categorize problems, in a sense each biological study is unique: being based on specific premises and hypotheses to be tested, giving rise to unique image data to be analyzed, and requiring dedicated image analysis methods in order to take full advantage of this data.
It seems to me that there is nothing here that would make these fields/methods/problems limited to biological applications (or medical).
All too often, scientific publications report the use of image analysis tools without specifying which algorithms were involved and how parameters were set, making it very difficult for others to reproduce or compare results.
I think it is the common attitude presented in the first quote that causes this problem. The solution is obvious:
Most of image analysis should be context independent.
In other words, it should be mathematical. Once mathematical issues are understood, image analysis becomes a tool, like a calculator or spreadsheet software.
P.S. I’ll try to rewrite the list and put it in the wiki under Fields related to Computer Vision.
March 21, 2008
In the last post I discussed a certain part of the article Quantitative Biological Image Analysis by Erik Meijering and Gert van Cappellen. I continue.
Image Analysis: image in -> features out. (Possibly several images in case of video or stereo vision.) Here are a few more image processing methods that are used for analysis:
- Morphology – erosions, dilations, etc. Repeated erosions will remove small particles then you can count the rest (“granulometry”). Repeated erosions that also preserve the topology will produce “skeletonization” of objects. Robustness of topology under morphological operations interests me a lot right now.
- “Colocalization” – evaluating the degree of overlap of two biological entities differently colored.
- Fourier transform – finding periodic patterns in the image. It tells you a lot about the textures present in the image.
- Image segmentation – finding objects in the image. There are many interesting methods (watershed, active contours, topology). It would be interesting to compare them some time in the future.
These are image processing tools used for image analysis but most of image processing/enhancement tools however are just that. Sometimes it works both ways:
- Boundaries of objects can be enhanced by means of edge detection.
- Fourier transform in combination with its inverse is used for denoising.
Computer Vision: image in -> interpretation out. Elsewhere in the article: “…image analysis… is defined as the act of measuring (biologically) meaningful object features in an image.” From this point of view,
image analysis = low level computer vision.
(BTW, that’s exactly the subject of our wiki.) Because of this overlap I prefer the term “computer vision” for this. “Analysis” is just too broad a term. Does finding the average color in the image qualify as analysis? Yes, of course. Does it tell as anything about the contents of the image? No, not a bit. I like this definition:
high level interpretation = image understanding.
There will be another post on the subject.
Update: In ImageJ’s Features page, under “Analysis” image segmentation or particle analysis isn’t even mentioned! “Analysis” means different things to different people.
March 13, 2008
I just finished reading Quantitative Biological Image Analysis by Erik Meijering and Gert van Cappellen (Chapter 2 of Imaging Cellular and Molecular Biological Functions, S. L. Shorte and F. Frischknecht (eds.), Springer-Verlag, Berlin, 2007, pp 45-70). It’s an excellent article! I especially liked the part that classify fields related to computer vision. I outline it below along with a few thoughts of my own. There are nice illustrations too but I won’t copy them.
Image Formation: object in -> image out. It may be important to know how the image was formed originally. The reason is that if you have a priori knowledge of the hardware that produced the image you may be able to use it to mitigate noise and imperfections (image processing below). However, it seems to me that the hardware manufacturers should be taking care of this.
Image Processing: image in -> image out. Smoothing, sharpening, blurring and de-blurring, other image enhancement, and on and on, hundreds of tasks with many different algorithms for each. Just take a look at Photoshop! Most of the ImageJ is also about image processing. Since the output is an image, the main purpose is to supply people with better looking images. A secondary purpose is preprocessing for image analysis to improve quality. The term “quality” is relative and depends on the context. One thing clear is that image processing leads to loss of information. That could harm your image analysis. So, you need insight into the problem to be sure that what you lose isn’t important. That insight comes from image analysis – full circle…
Image Analysis: image in -> features out. Let’s start with “dual purpose” image processing tasks. These operations are also image analysis tools:
- Intensity transformation – the value of each pixel is replaced with another value that depends only on the initial value. The main application is binarization (via thresholding or otherwise) as many image analysis tasks are applicable only to binary images.
- Local filtering - the value of each pixel is replaced with another value that depends only on the values of pixels in a certain neighborhood of this pixel. One of the main applications is edge detection (pixels where the values are changing the fastest). Morphology is another method of detecting edges (dilated version minus eroded version) but is limited to binary images. Unfortunately, neither method guarantees an unbroken sequence of edges. As a result, it may be impossible to reconstruct the object this sequence is supposed to surround.
There is more here than I expected. In the next installment:
- More of Image Analysis,
- Computer Graphics,
- Computer Vision, and
- Visualization.
March 4, 2008
In the last post I provided a list that compared the capabilities of ImageJ (without plug-ins) and Pixcavator 2.4 in analysis of gray scale images. Then I submitted the link to the ImageJ’s forum.
The premise was very simple. The list contained enough features of ImageJ’s to show that they are comparable (in a certain narrow sense). It also contained some Pixcavator’s features that ImageJ doesn’t have to make the comparison interesting. I expected people to try it and give me some feedback. This is done every day because it’s a fair trade: people get to try something new and I get to learn something new. That didn’t happen.
My post was taken as an attack on ImageJ. The responses were along these lines:
- ImageJ is free (as in “free speech” as I was explained).
- ImageJ works on all platforms not just Windows.
- ImageJ’s plug-ins include “particle tracking, deconvolution, fourier transform, FRET analysis, 3D reconstruction, neuron tracing…”
Clearly, this wasn’t the kind of feedback I expected. I thought they were simply off topic.
To resolve the issue somewhat I added the first two items to the table and also promised to have a post to compare ImageJ with plug-ins to Pixcavator SDK (it’s free but unlike free speech it will only stay free for some time…).
Even though this was very unsatisfying, it wasn’t all bad - there were a few positive/neutral responses (thanks!) and there were spikes in the number of visits and downloads.
In retrospect, I should have made it clear that the comparison was from the point of view of a user not a developer. In this light, the main advantage of Pixcavator becomes evident – its simplicity!
So I didn’t learn anything new and didn’t get to improve my software, so what? I can turn this around and say that the end result is in fact a good news:
None of the statements in the post has been refuted.
The only statement that has been refuted – multiple times – is: “Pixcavator is better than ImageJ”, the statement I never made or implied.
One interesting reaction came from Mark Burge: “I would hazard to say that everything in Pixcavator is surely available through a plugin”. I wagered $100 that he was wrong. No response so far. How about we make this a bit more interesting? Here’s is a challenge:
$300 for the first person who shows that all of these features of Pixcavator’s are reproducible by the existing ImageJ’s plug-ins!
Meanwhile life goes on. We had a couple of milestones recently. First, we reached 30,000 downloads of Pixcavator since January 2007 (versions 2.2 – 2.4). Second, the wiki - the main page – has been visited 10,000 times since August 2007. Recently we are getting over 80 daily visitors.
February 27, 2008
Here we compare the capabilities of ImageJ (without plug-ins) and Pixcavator 2.4 in analysis of gray scale images. The links will take you to the relevant articles in the wiki. Update: The list is addressed mostly to the users. For the developers, there will be a similar list comparing ImageJ (including plug-ins) and Pixcavator SDK.
|
Tasks and features
|
ImageJ
|
Pixcavator
|
|
Analysis of the gray scale image after binarization
|
Yes
|
Yes
|
|
Computation of binary characteristics of objects/particles
|
Yes
(A specific binarization has to be found first by thresholding or another method.)
|
Yes
(The characteristics are computed for all possible thresholds.)
|
|
size/area
|
Yes
|
Yes
|
|
circularity/roundness
|
Yes
|
Yes
|
|
centroid
|
Yes
|
Yes
|
|
perimeter
|
Yes
|
Yes
|
|
bounding rectangle
|
Yes
|
No
(Useless for such applications as microscopy where the results should be independent of orientation)
|
|
|
|
|
|
Analysis of the gray scale image without prior binarization
|
Limited
|
Yes
|
|
Detection of objects as max/min of the gray scale
|
Yes
|
Yes
|
|
Filtering detected objects (in order to deal with noise etc)
|
Yes
(with respect to contrast only)
|
Yes
(with respect area, contrast, roundness, and saliency)
|
|
Counting objects/particles
|
Yes
|
Yes
|
|
Image segmentation method
|
Watershed - for either max or min but not both (dark or light objects but not both)
|
Topology (both dark and light objects)
|
|
Computation of gray scale characteristics of objects
|
No
|
Yes
|
|
contrast
|
No
|
Yes
|
|
center of mass
|
No
|
Yes
|
|
saliency/mass
|
No
|
Yes
|
|
average contrast
|
No
|
Yes
|
|
|
|
|
|
Automatic analysis
|
Yes
|
Yes
|
|
Semi-automatic mode
|
No
|
Yes
(based on objects found for all possible thresholds)
|
|
Manual mode
|
No
|
Yes
(full control over found objects)
|
|
User interface
|
Hundreds of commands in drop down menus
|
4 sliders, 7 buttons
|
|
User experience (mine)
|
“Wrong image format!”
“Threshold first!”
“Results unsatisfactory? Start over!”
|
Move sliders, click buttons
Try it!
|
|
Screenshots
|
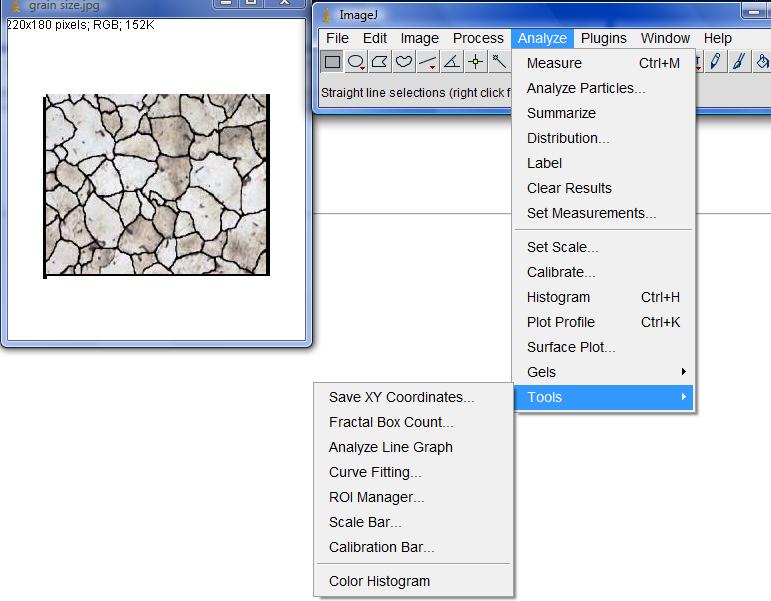
|
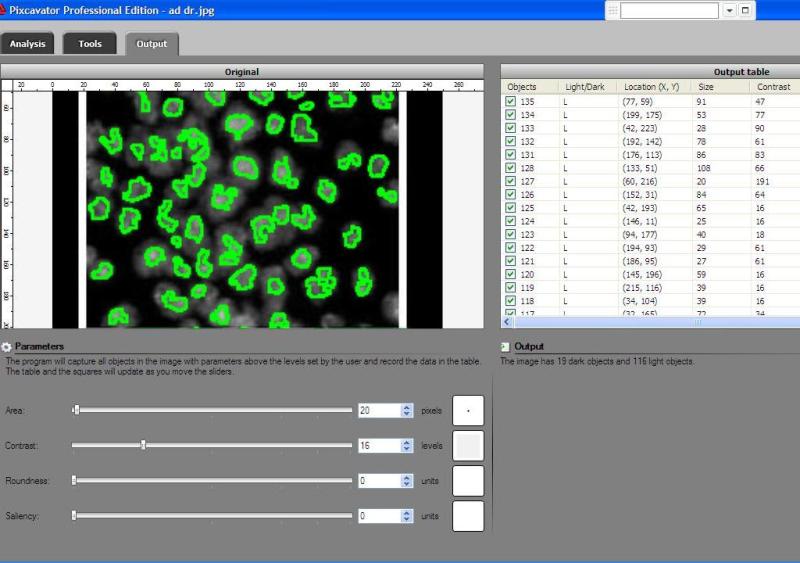
|
Update: The main criticism has been that some positive things about ImageJ are missing from the table. They are added below (not about image analysis but still). On the other hand, none of the statements in the above part has been questioned.
|
|
|
Platforms
|
Windows, Mac, Linux
|
Windows only (cellAnalyst web application soon to come)
|
Price
|
Free
|
$150 (free trial)
|
— Next Page » |
|
|










")


