





Image segmentation: binary watershed
According the ImageJ site: “Watershed segmentation is a way of automatically separating or cutting apart particles that touch”.
Suppose black is the particles and white is the background. The the procedure is fairly simple.

First, for each pixel compute the distance to the nearest white pixel. This is called the distance function. It’s a scalar function of two variables.
Next, find the maximum points of this function. Each of these pixels will become the center of a particle.
You carry out multiple rounds of dilation that gradually grow these particles. The dilation has two restrictions. First, the particles aren’t allowed to grow beyond the original set of black pixels. This way we guarantee that we end up with the same set of pixels except it has been “cut” into pieces. Second, a new pixel isn’t added if it’s adjacent to a pixel that belongs to another particle. This way the particles start to “push” onto each other but never overlap.
The tricky part of the last restriction is that the growth rate will have to be different for particles of different sizes. Otherwise, two particles will always be separated by a cut exactly half way between their centers. That wouldn’t make sense if one is significantly larger than the other. Roughly, the dilation rate should be proportional to the value of the distance function.


Some questions remain. For example, how does one efficiently find the maxima? Everything is discrete, so forget about partial derivatives etc. You have to visit every point.
How does one deal with particles that are simply noise? If you remove all small particles, you may have nothing left. One answer is to discard the maxima with low values of the distance function.
Another issue is typical for many image analysis techniques. Once again to quote the ImageJ site, “Watershed segmentation works best for smooth convex objects that don’t overlap too much.” Basically, you have to view (analyze!) the image yourself and decide ahead of time whether the method is appropriate. There is a good reason to be cautious – non-convex particles may cause the watershed method to produce undesirable results.
You have to choose ahead of time whether you have white or black particles. If you don’t do it correctly, you end up with non-convex black “particles”. The result of watershed segmentation isn’t what you expect:


It is also easy to think of an image (rings) that can’t possibly be analyzed correctly by watershed regardless of the black/white choice:

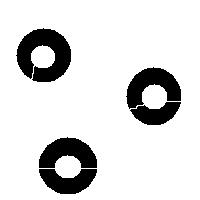
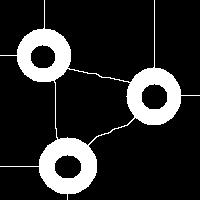
Needless to say that the topological method produces the correct segmentation here:


It can’t however separate particles yet (the stuff will appear in the wiki under Robustness of topology).
Top finds
- Casinos Not On Gamstop
- Non Gamstop Casinos
- Casino Not On Gamstop
- Casino Not On Gamstop
- Non Gamstop Casinos UK
- Casino Sites Not On Gamstop
- Siti Non Aams
- Casino Online Non Aams
- Non Gamstop Casinos UK
- UK Casino Not On Gamstop
- Non Gamstop Casino UK
- UK Casinos Not On Gamstop
- UK Casino Not On Gamstop
- Non Gamstop Casino UK
- Non Gamstop Casinos
- Non Gamstop Casino Sites UK
- Best Non Gamstop Casinos
- Casino Sites Not On Gamstop
- Casino En Ligne Fiable
- UK Online Casinos Not On Gamstop
- Online Betting Sites UK
- Meilleur Site Casino En Ligne
- Migliori Casino Non Aams
- Best Non Gamstop Casino
- Crypto Casinos
- Casino En Ligne Belgique Liste
- Meilleur Site Casino En Ligne Belgique
- Bookmaker Non Aams
- カジノ ライブ
- онлайн казино с хорошей отдачей
- スマホ カジノ 稼ぐ
- ブック メーカー オッズ
- Top 3 Nhà Cái Uy Tín Nhất
- Trang Web Cá độ Bóng đá Của Việt Nam
- Casino En Ligne Avis
- Casino En Ligne France
- Casino En Ligne
- 꽁머니 토토
- Casino Online Non Aams
- Migliori Casino Non AAMS
- Meilleur Casino En Ligne
- Casino En Ligne France Légal
- Casino En Ligne France Légal
- Casinos En Ligne
- Mejores Casinos Online









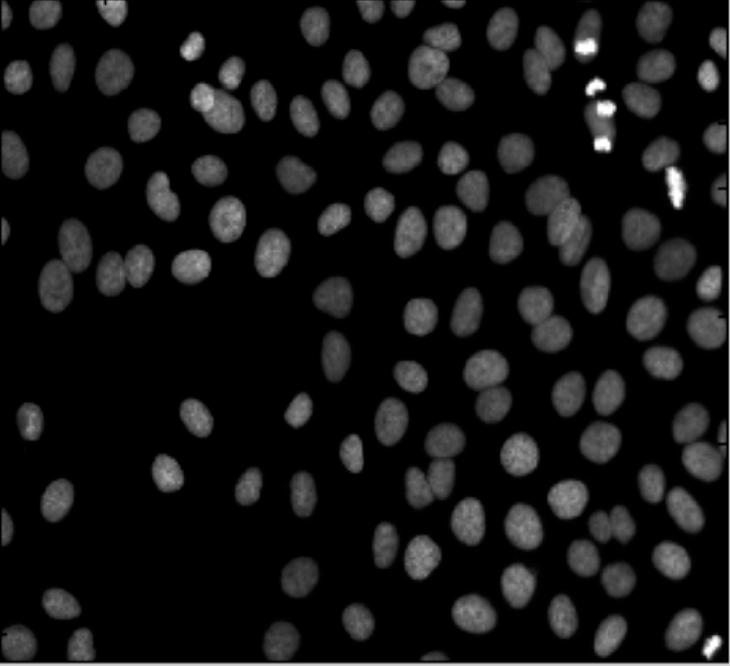 This description isn’t what I would call a definition as it suffers from a few very serious flaws.
This description isn’t what I would call a definition as it suffers from a few very serious flaws. More nitpicking. Do the regions have to be “multiple”? The image may be blank or contain a single object. Does the image has to be “digital”? Segmentation of analogue images makes perfect sense.
More nitpicking. Do the regions have to be “multiple”? The image may be blank or contain a single object. Does the image has to be “digital”? Segmentation of analogue images makes perfect sense. Microarrays (microplates etc) are plastic rectangles with a grid of “wells” containing biological materials. When another biological or chemical substance is added to these cells, the reaction is captured in digital images. For example, various concentrations of a chemical or a drug are added to the wells containing biological cells. The cells then start to divide faster, or slower, or simply die. The result affects the color of the substance in each cell. The image analysis automatically captures this data and draws conclusions. For example, you can pinpoint exactly at what concentration the drug becomes toxic. It’s like hundreds experiments in one! Appropriately, this is also called
Microarrays (microplates etc) are plastic rectangles with a grid of “wells” containing biological materials. When another biological or chemical substance is added to these cells, the reaction is captured in digital images. For example, various concentrations of a chemical or a drug are added to the wells containing biological cells. The cells then start to divide faster, or slower, or simply die. The result affects the color of the substance in each cell. The image analysis automatically captures this data and draws conclusions. For example, you can pinpoint exactly at what concentration the drug becomes toxic. It’s like hundreds experiments in one! Appropriately, this is also called 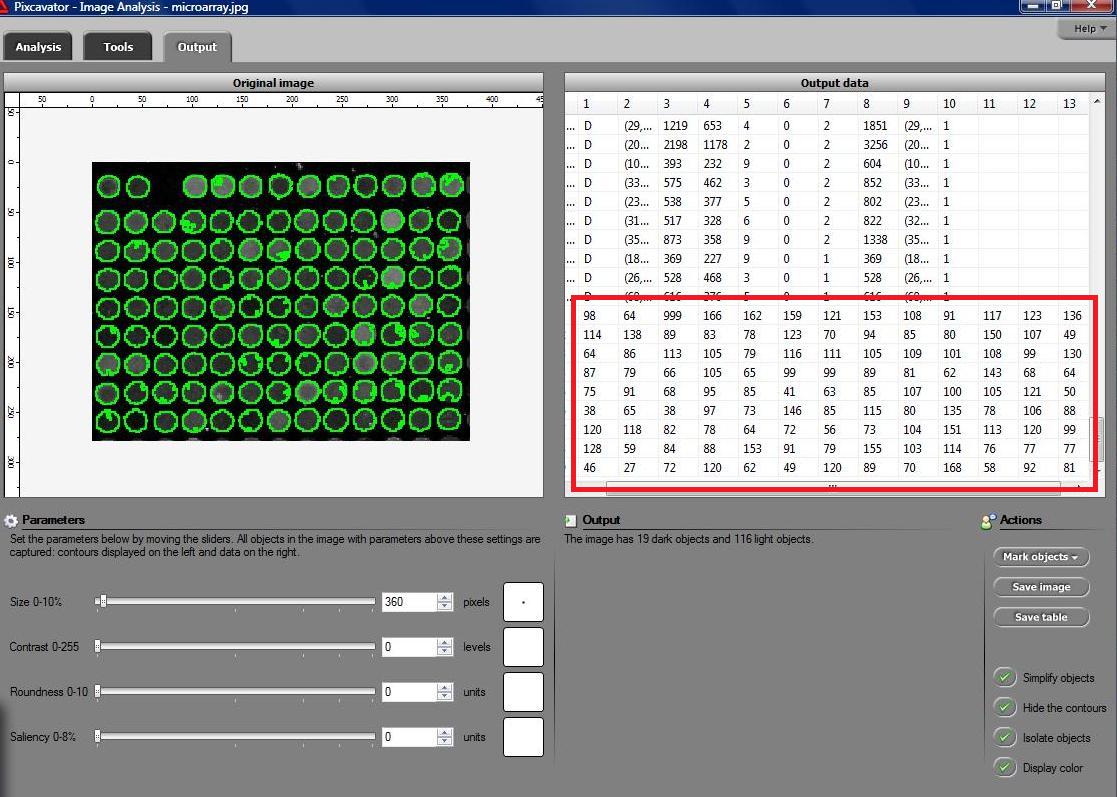



")


